« Supposons qu’existe une machine surpassant en intelligence tout ce dont est capable un homme, aussi brillant soit-il. La conception de telles machines faisant partie des activités intellectuelles, cette machine pourrait à son tour créer des machines meilleures qu’elle-même ; cela aurait sans nul doute pour effet une réaction en chaîne de développement de l’intelligence, pendant que l’intelligence humaine resterait presque sur place. Il en résulte que la machine ultra intelligente sera la dernière invention que l’homme aura besoin de faire, à condition que ladite machine soit assez docile pour constamment lui obéir. »
(Irving John Good, « Speculations Concerning the First Ultraintelligent Machine », Advances in Computers, vol. 6, 1966)
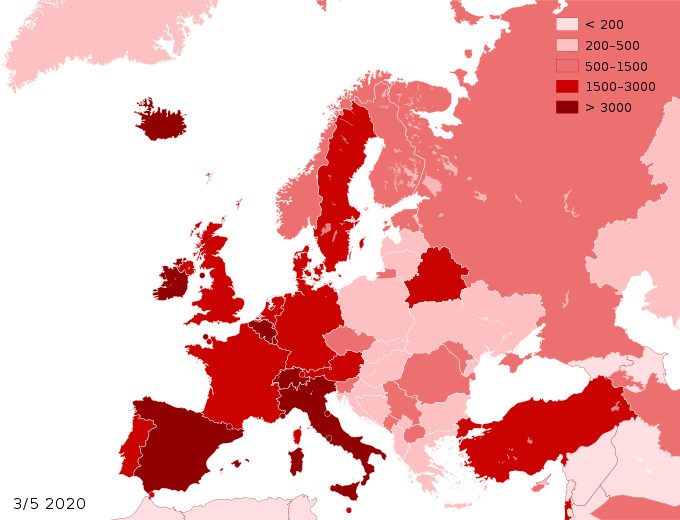
Entre fantasmes, mystifications, erreurs (volontaires ou non), flagorneries marketing, peurs, etc., l’Intelligence Artificielle (IA) entre maintenant dans sa phase de (’ap)préhension par le droit positif, direct et réel: le 21 avril 2021, la Commission européenne a publié sa proposition de règlement établissant des règles harmonisées sur l’IA.
Un défi de taille, fondé sur un travail de plusieurs années, dont les aspects à réguler sont importants.
Nous n’entrerons pas ici dans le subtil écueil évité par la Commission, qui vise « seulement » les « systèmes d’intelligence artificielle » et non le terme flou, voire flexible, d’« intelligence artificielle », seul. Ni nous ne traiterons des définitions, des responsabilités et leurs exceptions telles que prévues par ce texte qui se veut fondateur d’une Europe résolument tournée vers l’avenir, dans la lignée des RGPD, DGA, DSA et DMA. Nous traiterons ces points dans de futures études.
Notre propos n’est ici que de rappeler quelques exemples et d’ouvrir le débat sur ce qu’a été, ce qu’est et ce que pourrait être l’IA.
Mythes & Réalités
« Tu ne feras point de machine à l’esprit de l’homme semblable ».
(Frank Herbert, Dune, 1965)
Du
Turc mécanique (1770, Wolfgang von Kempelen, inventeur),
Présenté comme un automate joueur d’échecs qui remportait de nombreuses parties en Europe et en Amérique (y compris contre des personnalités comme Napoléon Bonaparte et Benjamin Franklin), cet « androïde » n’était qu’une supercherie assez maline ne fonctionnant que par le truchement d’un véritable joueur (humain) qui se cachait en son sein;
en passant par
Frankenstein (1818, Mary Shelley, écrivain)
Premier être créé moderne qui pousse les mythes de Galatée ou du Golem au paroxysme de la solitude et du rejet;
et
Le Test de Turing (1950, Alan Turing, cryptologue),
Jamais vraiment vérifié mais qui permettrait de déterminer si vous discutez avec un ordinateur ou un humain (l’ordinateur ayant alors pour but de vous convaincre de son humanité) et donc de poser la question existentielle : « une machine peut-elle penser ? »;
jusqu’à
2001, l’Odyssée de l’espace (1968, Stanley Kubrick, réalisateur),
Avec un ordinateur, HAL, qui se sentant menacé par les humains, avec qui pourtant il collabore, décide de tous les tuer avant que le dernier astronaute ne le débranche; HAL avoue alors sa peur, son émotion de sentir son intelligence lui échapper (si l’humain s’en sort, ce n’est pas à cause de son intelligence rationnelle, mathématique, mais grâce à sa réactivité et à son imagination);
l’IA nous interroge depuis le longtemps que ce soit sur le terrain de l’imitation, de l’émancipation ou de la cohabitation avec des entités étranges, étrangères et pourtant de plus en plus familières…
… 1966
Le test de Turing est réussi par la machine ELIZA. Mais il apparait que ce test n’est pas suffisant puisque la machine ne « pense pas », elle imite juste les humains.
… 1997
Deep Blue, l’ordinateur d’IBM, bat le champion du monde d’échecs russe Garry Kasparov au cours d’un match en six parties. Après la cinquième manche, Kasparov était si découragé qu’il expliqua : «Je suis un être humain. Lorsque je vois quelque chose qui dépasse mon entendement, j’ai peur. ».
Mais Deep Blue était, en fait, assez bête. Sa seule véritable force résidait dans sa capacité de calcul (deux cents millions de positions par seconde) et sur la plus vaste base de données de parties de tous les temps. Ces décisions ne suivent donc, si on simplifiait, qu’un simple arbre de décision, chaque coup étant le meilleur possible au vu des parties enregistrées.
… 2016
AlphaGo, développé par DeepMind Technologies, une société britannique d’IA rachetée par Google en 2014, est le premier programme informatique à battre unjoueur professionnel de go de haut vol. Techniquement un pas est clairement franchi: AlphaGo utilise une recherche arborescente Monte Carlo et des réseaux de neurones artificiels pour apprendre et jouer.
12 mois après cette victoire, une nouvelle version appelée AlphaGo Zero apprit le go en jouant contre elle-même des millions de parties, sans recourir à des données tirées de parties disputées entre humains : elle écrase rapidement AlphaGo.
… 2017
Au Texas hold’em, variante du Poker, contrairement aux échecs ou au go, les joueurs ne voient pas tout ce qui se passe : chaque joueur reçoit 2 cartes fermées (visibles par lui seul) au début de chaque partie; progressivement s’ajoutent 5 cartes ouvertes (visibles par tous) au milieu de la table. Pour avoir la meilleure main, il est nécessaire d’avoir la meilleure combinaison possible de 5 cartes parmi les 7 dont le joueur dispose. Les joueurs ont donc une information imparfaite, ce qui rend le jeu particulièrement complexe pour les machines et nécessite une forme d’« intuition » pour déterminer quelles sont les stratégies gagnantes.
En dépit de ces difficultés, une IA nommée DeepStack est parvenue à l’emporter sur des joueurs de poker professionnels (en un contre un, sans limites). Pour exercer des réseaux de neurones artificiels et développer en amont une intuition au poker, l’IA a utilisé le deep learning : elle a joué des millions de parties de poker contre elle-même, générées de façon aléatoire.
Toujours en 2017, une autre IA de poker appelée Libratus bat quatre des joueurs de Texas hold’em les mieux classés au cours de nombreuses parties jouées pendant une compétition sur plusieurs jours. Libratus n’utilisait pas les réseaux de neurones, mais une approche algorithmique appelée minimisation du regret hypothétique (après chaque partie simulée, le programme réinterroge ses décisions et trouve des manières d’améliorer sa stratégie).
Ces simples exemples montrent la diversité de l’IA, les ramifications de cette discipline qui explore les données, les analyse et, parfois, prend des décisions surprenantes.
Mais l’IA telle que nous la connaissons reste, encore aujourd’hui, une Intelligence Artificielle faible, par opposition à l’IA forte, qui n’existe pas encore. Si les machines sont capables de reproduire un comportement humain, elle n’en ont pas (encore) conscience. Il est possible que leurs capacités puissent croître au point de se transformer en machines dotées de conscience, de sensibilité et d’esprit mais nous n’y sommes certainement pas (comme nous ne nous sommes toujours pas implantés sur Mars, mais cela se précise…).
Ce qu’il faut retenir c’est que l’IA a beaucoup évolué grâce, notamment, à l’émergence du Cloud Computing et du Big Data, soit d’une puissance de calcul peu coûteuse et de l’accessibilité à un grand nombre de données. Nous restons cependant à un stade d’apprentissage statistique plus que d’une véritable « organisation du réel en pensée ».
Les progrès sont considérables et désormais bien répertoriés :
- Transport (véhicules autonomes),
- Finance (personnalisation de plan d’investissement – trading haute fréquence),
- Santé (diagnostics – opérations),
- Communication (enceintes intelligentes),
- Consommation (analyse des comportements),
- Sécurité (biométrie),
Etc, etc…
Les domaines où l’IA intervient et interviendra sont infinis.
Aussi l’humanité devra-t-elle être particulièrement prudente dans le développement de systèmes autonomes et dans la confiance excessive dans les technologies aux mécanismes parfois impénétrables.
Risques & Questions
« La maîtrise du risque exige de passer par son identification. »
Rémy JULIENNE, cascadeur (17 avril 1930 – 21 janvier 2021)
Des études montrent en effet qu’il est possible de « tromper » certains systèmes d’imagerie en les faisant à tort identifier un bus scolaire comme étant une autruche, et ce en altérant les images d’une manière imperceptible pour l’homme.
Premier problème : il est donc impossible de repérer que le système va mal interpréter ce qu’il va percevoir.
Aujourd’hui, nul ne peut en effet assurer qu’un reflet sur un toit ou la montre d’un passant ne pourra produire une perturbation et donc complètement tromper le système de reconnaissance d’image d’une voiture autonome. Une erreur qui pourrait être fatale. Si un terroriste parvenait à faire en sorte qu’un centre commercial ou un hôpital ressemble à une cible militaire pour un drone, les conséquences pourraient être tout aussi dramatiques.
Second problème : dans de très grand nombre de cas, on ne sait ni pourquoi ni comment le logiciel se trompe aussi systématiquement.
Comment alors avoir confiance en ces systèmes parfois impénétrables ?
Si nous nous en remettons de plus en plus aux IA, avec de plus en plus de réseaux neuronaux d’apprentissage profond, il est alors crucial de développer des systèmes susceptibles d’expliquer comment ils sont parvenus à telle ou telle décisions. Cependant, certaines IA peuvent créer des modélisations de la réalité bien plus complexes que ce que les humains peuvent comprendre. L’expert en IA David Gunning a même suggéré que le système le plus « performant sera vraisemblablement le moins explicable ».
A l’heure des algorithmes modernes de deep learning, constitués de millions de neurones artificiels et qui une fois entraînés fonctionnent en mode “boite noire”, même ceux/celles qui les ont conçus ne peuvent interpréter facilement les résultats de leur fonctionnement.
Comment justifier un refus de prêt décidé par un algorithme ? Et comment comprendre que cette voiture autonome a décidé une manœuvre extrêmement risquée, au prix de dégâts matériels ou même humains ? Même si c’est la bonne décision, comment faire confiance à une intelligence artificielle lorsque celle-ci fait un diagnostic contraire à celui d’un médecin spécialiste ?
C’est probablement ici le point de bascule, entre performance et confiance. La compréhension des modèles, l’explicabilité (décomposition / explication), des algorithmes est probablement, aujourd’hui, la voie à privilégier.
Mais, ne l’oublions pas, pour le commun des mortels ces informations sont parfois inintelligibles. Et pour que les explications soient faciles d’accès, il faudrait pouvoir distinguer
- Une explication « locale », « ex post », c’est-à-dire relative à une décision spécifique,
Par opposition à
- Une explication « globale » ou « ex ante », c’est-à-dire portant sur l’ensemble du processus algorithmique.
En effet, en règle générale, il semble assez évident qu’en tant que non spécialiste, la compréhension de l’algorithme m’importe peu alors que la justification de la décision prise à mon égard est primordiale.
Les concepteurs d’IA avec des présentations simples et intelligibles doivent pouvoir montrer des paramètres qui ont conduit à une décision.
Tout le monde d’ailleurs gagnera a plus de transparence.
Premières conclusions
Stephen Hawking prédisait dans une interview à la BBC en 2014 : « Le développement d’une intelligence artificielle totale pourrait sonner le glas de la race humaine. (…) Elle prendrait son essor toute seule et se transformerait elle-même à une vitesse croissante. » Autrement dit, il se peut que les IA deviennent si intelligentes et compétentes qu’elles soient capables de s’améliorer sans cesse, créant une forme de super intelligence susceptible de menacer l’humanité. Cette forme d’emballement de la croissance technologique, qu’on appelle parfois la singularité technologique, pourrait donner lieu à des changements inimaginables de la civilisation, de la société et de la vie humaine.
L’une des questions n’est donc pas de s’opposer mais de comprendre comment les humains s’intégreront à un monde où les IA nous entoureront de plus en plus. Que voudra dire être « humain » dans un siècle ? Si les méthodes et les modélisations de l’IA sont déjà utilisées pour nous aider à décider qui embaucher, qui fréquenter, qui libérer, et comment rendre autonome la conduite des voitures et des drones, quelle part de contrôle sur nos vies céderons-nous aux IA du futur ?
Alors qu’elles prennent de plus en plus de décisions pour nous, les IA pourront-elles se laisser abuser et faire des erreurs graves ? Qui en justifiera et sera finalement responsable ?
Avant de s’interroger sur l’âme des machines, il nous faut peut-être questionner la nôtre….
« Science sans conscience n’est que ruine de l’âme » François Rabelais
Bibliographie
https://www.linflux.com/litterature/ia-et-sf-les-liaisons-dangereuses/
https://www.strategie.gouv.fr/point-de-vue/lintelligence-artificielle-mythes-realites
https://ec.europa.eu/france/news/20210421/nouvelles_regles_europeennes_intelligence_artificielle_fr
https://www.lebigdata.fr/intelligence-artificielle-ue-garantie-humaine
https://rm.coe.int/primer-fr-new-cover-pages-coe-french-compressed-2757-0674-1252-v-1/1680a2fd4b
« ARTIFICIAL INTELLIGENCE, AN ILLUSTRATED HISTORY » by Clifford Pickover



Benjamin MARTIN-TARDIVAT
Spécialisé dans la protection des données personnelles, il intervient comme Data Protection Officer (« DPO ») auprès de nombreuses sociétés et associations françaises et étrangères. Il forme étudiants, créateurs d’entreprises et administrations afin de les sensibiliser aux problématiques du droit d’auteur, de la propriété industrielle et de la protection des données dans la société de l’information et l’impact des nouvelles technologies et de l’IA dans ces domaines.





















































![[DSA, AI Act] Régulation, et si l’Europe avait raison ? Podcast les Eclaireurs du Numérique avec Jean-Marie Cavada](https://idfrights.org/wp-content/uploads/2023/12/8c234391-01e8-40d4-9608-4ea6c80d4f11-440x264.jpg)