2 mai 2022
Notre Institut a pour vocation de défendre, promouvoir et protéger les droits fondamentaux des individus dans le monde digital et la souveraineté numérique des entreprises. S’agissant de notre première vocation, la Charte de l’Union Européenne y a déjà consacré un article principal (l’article 8). Cependant, il est très général, ce qui a contraint tant l’U.E. que les Etats membres à légiférer abondamment, mais de manière trop catégorielle et parcellaire. Néanmoins nous saluons les dispositifs légaux récemment instaurés par l’Union européenne pour, d’une part, réguler l’utilisation de nos données personnelles avec le Règlement Général sur la protection des données de 2018 (encore améliorable pour les PME/TPE…) et d’autre part, établir des règles de concurrence équitables pour les entreprises du numérique grâce au Digital Markets Act de 2022. Nous actons également la finalisation du Digital Services Act qui a pour but de réguler les contenus en créant un espace numérique plus protecteur des droits fondamentaux des utilisateurs.
Alertée et soutenue par l’opinion publique, l’Union européenne a été pionnière dans sa volonté de mettre fin à la toute-puissance des géants du numérique sur nos vies, nos modes de consommation et les équilibres de nos démocraties. Dans ce cadre, notre Institut a décidé de mettre en oeuvre le processus devant conduire à la rédaction d’une Charte des Droits Fondamentaux du numérique, dont les premiers jalons ont été posés dans un document très complet, élaboré par Marin De Nebehay, joint à cet article introductif.
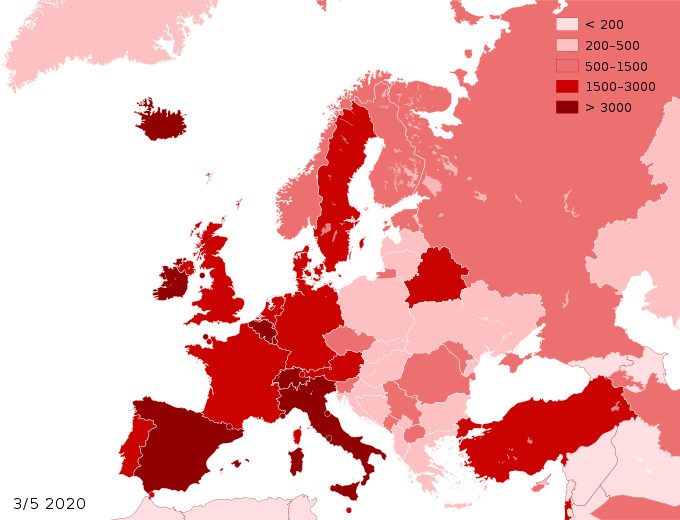
Ce combat est d’autant plus important que la syndémie de coronavirus a accru notre dépendance aux grandes plateformes et à leurs intelligences artificielles. Désormais, des pans entiers de nos vies dépendent de ces programmes informatiques capables de simuler nos facultés cognitives grâce à d’importantes opérations statistiques. Nous utilisons déjà ces machines pour minimiser les risques dans les domaines de la santé, de la sécurité, de l’éducation, de l’économie, de la conduite automobile…
Nous acceptons progressivement l’idée selon laquelle la rationalisation mathématique artificielle est supérieure à la raison humaine biologique. À terme, l’idée même d’avoir recours à la raison humaine nous paraitra dangereuse. Cette soumission consentie de la raison à la calculabilité est d’autant plus accrue que le machine learning permet à ces « cerveaux » d’apprendre et d’évoluer en permanence sans nous.
L’implémentation généralisée des intelligences artificielles dans nos vies ouvre peu à peu la voie à l’instauration d’une gouvernance algorithmique fondée sur le profilage des individus plutôt que sur la politique, le droit ou les normes sociales. Au nom de la fin du risque, les gouvernements cesseront de diriger les individus au nom du bien commun afin de gérer des profils de données au nom de la sécurité. Notre humanité cessera ainsi d’être une fin à protéger, pour devenir un problème à traiter avec, à terme, le risque de vouloir la normer définitivement. C’est l’avènement d’un très réel Léviathan ! autrement plus dangereux que la privation de la liberté d’aller et venir pendant quelques semaines, ou que l’obligation de mettre un masque et/ou de se faire vacciner.
C’est en effet un Léviathan qui, non seulement nous gouvernera en nous disant ce que nous devons faire, mais également ce que nous devons être. Ce, pour notre bien, dont ce Monstre pourra soutenir qu’il a été élaboré par nous, c’est-à-dire à partir de ce que nous sommes : NOS DONNÉES ! De surcroit, ce Léviathan, outre qu’il méprise nos données objectives, autrement dit, tout ce que nous produisons, du simple son à toute œuvre matérielle, s’empare, s’approprie, notre moi le plus profond, tout ce qui touche à notre être, à notre personne, donc par nature incessible. Et, ce faisant, les géants du numérique valorisent considérablement des « biens » qui ne devraient pas l’être, et capitalisent gigantesquement sur ces biens appelées « données ». Ainsi, cette captation illégale est noyée dans l’utilisation des autres données, cessibles celles-là, bien qu’ils « oublient » de les rémunérer très souvent…
Pour lutter contre cette menace, il faut évidemment continuer à protéger nos données personnelles objectives. C’est le seul moyen pour nous de nous prémunir de tout profilage algorithmique, fondement essentiel d’une gouvernance cybernétique. Aujourd’hui, la législation actuelle ne nous le permet pas.
L’action de notre institut doit continuer de plus belle sur ce terrain. Cependant, il y a lieu d’initier un combat pour que les grands (et les moyens !) acteurs du numérique ne puissent plus impunément s’emparer de nos données subjectives, en clair de notre personnalité ! Et en faire leur miel.
Le travail effectué par le Comité Europe de l’Institut, préparé par Marin De Nebehay a permis d’affiner l’analyse embryonnaire évoquée ci-dessus. Nous tenons à souligner que les dispositifs classiques de protection des droits de la personnalité ne sont pas étendus au numérique : nom, goûts, secret des correspondances, droit à l’intimité de la vie privée, opinion politique, droit à l’image, etc. Cette nouvelle protection extrairait pourtant pour toujours certaines de nos données personnelles de la sphère digitale afin d’empêcher tout profilage ou à tout le moins pourrait être utilisée pour faire payer- chèrement si possible- les acteurs du numérique qui s’y livrent avec notre assentiment tacite, mais sans notre accord express ! C’est donc cette extension de la protection des droits de la personnalité qui sera, à n’en pas douter la grande étape à atteindre. Notre institut y travaille ardemment et toutes les bonnes volontés sont appelées à apporter leur compétence.
Jean-Pierre Spitzer,
Avocat
Vice -Président et Président du comité Europe d’iDFrights
Avec la collaboration de Marin De Nebehay
Terme utilisé par la revue médicale The Lancet pour décrire l’épidémie de Coronavirus-19.
2 Le machine learning permet à l’intelligence artificielle de découvrir des motifs récurrents dans des grands ensemble de données (chiffres, mots, images, statistiques, etc.). Grâce à cela elle pourra apprendre de manière autonome à effectuer de nouvelles tâches et à s’améliorer.
3 Nous avions déjà alerté sur ce sujet par un article paru sur notre site et dans les Echos du 21/11/21























































![[DSA, AI Act] Régulation, et si l’Europe avait raison ? Podcast les Eclaireurs du Numérique avec Jean-Marie Cavada](https://idfrights.org/wp-content/uploads/2023/12/8c234391-01e8-40d4-9608-4ea6c80d4f11-440x264.jpg)